7장: 분산 학습
DGL은 데이터와 연산을 컴퓨터 리소스들의 집합들에 분산하는 완전한 분산 방식을 채택하고 있다. 이 절에서는 클러스터 설정(컴퓨터들의 그룹)을 가정하고 있다. DGL은 그래프를 서브 그래프들로 나누고, 클러스터의 각 컴퓨터는 한개의 서브 그래프 (또는 파티션)에 대해 책임을 진다. DGL은 클러스터이 모든 컴퓨터에서 동일한 학습 스크립트를 실행해서 계산을 병렬화시키고, trainer에게 파티션된 데이터를 제공하기 위해서 같은 컴퓨터에서 서버들을 실행한다.
학습 스크립트를 위해서 DGL은 미니-배치 학습과 비슷한 분산 API를 제공한다. 이는 단일 컴퓨터에서 미니-배치 학습을 수행하는 코드를 아주 조금만 수정하면 되게 해준다. 아래 코드는 GraphSAGE를 분산 형태로 학습하는 예제이다. 유일한 코드 변경은 4-7 라인이다: 1) DGL의 분산 모듈 초기화하기, 2) 분산 그래프 객체 생성하기, 3) 학습 셋을 나누고 로컬 프로세스를 위해서 노드들을 계산하기. 샘플러 생성, 모델 정의, 학습 룹과 같은 나머지 코드는 mini-batch training 과 같다.
import dgl
import torch as th
dgl.distributed.initialize('ip_config.txt')
th.distributed.init_process_group(backend='gloo')
g = dgl.distributed.DistGraph('graph_name', 'part_config.json')
pb = g.get_partition_book()
train_nid = dgl.distributed.node_split(g.ndata['train_mask'], pb, force_even=True)
# Create sampler
sampler = NeighborSampler(g, [10,25],
dgl.distributed.sample_neighbors,
device)
dataloader = DistDataLoader(
dataset=train_nid.numpy(),
batch_size=batch_size,
collate_fn=sampler.sample_blocks,
shuffle=True,
drop_last=False)
# Define model and optimizer
model = SAGE(in_feats, num_hidden, n_classes, num_layers, F.relu, dropout)
model = th.nn.parallel.DistributedDataParallel(model)
loss_fcn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
# training loop
for epoch in range(args.num_epochs):
for step, blocks in enumerate(dataloader):
batch_inputs, batch_labels = load_subtensor(g, blocks[0].srcdata[dgl.NID],
blocks[-1].dstdata[dgl.NID])
batch_pred = model(blocks, batch_inputs)
loss = loss_fcn(batch_pred, batch_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
컴퓨터들의 클러스터에서 학습 스크립트를 수행할 때, DGL은 데이터를 클러스터의 컴퓨터들에 복사하고 모든 컴퓨터에서 학습 잡을 실행하는 도구들을 제공한다.
Note: 현재 분산 학습 API는 PyTorch 백앤드만 지원한다.
DGL은 분산 학습을 지원하기 위해서 몇 가지 분산 컴포넌트를 구현하고 있다. 아래 그림은 컴포넌트들과 그것들의 인터엑션을 보여준다.
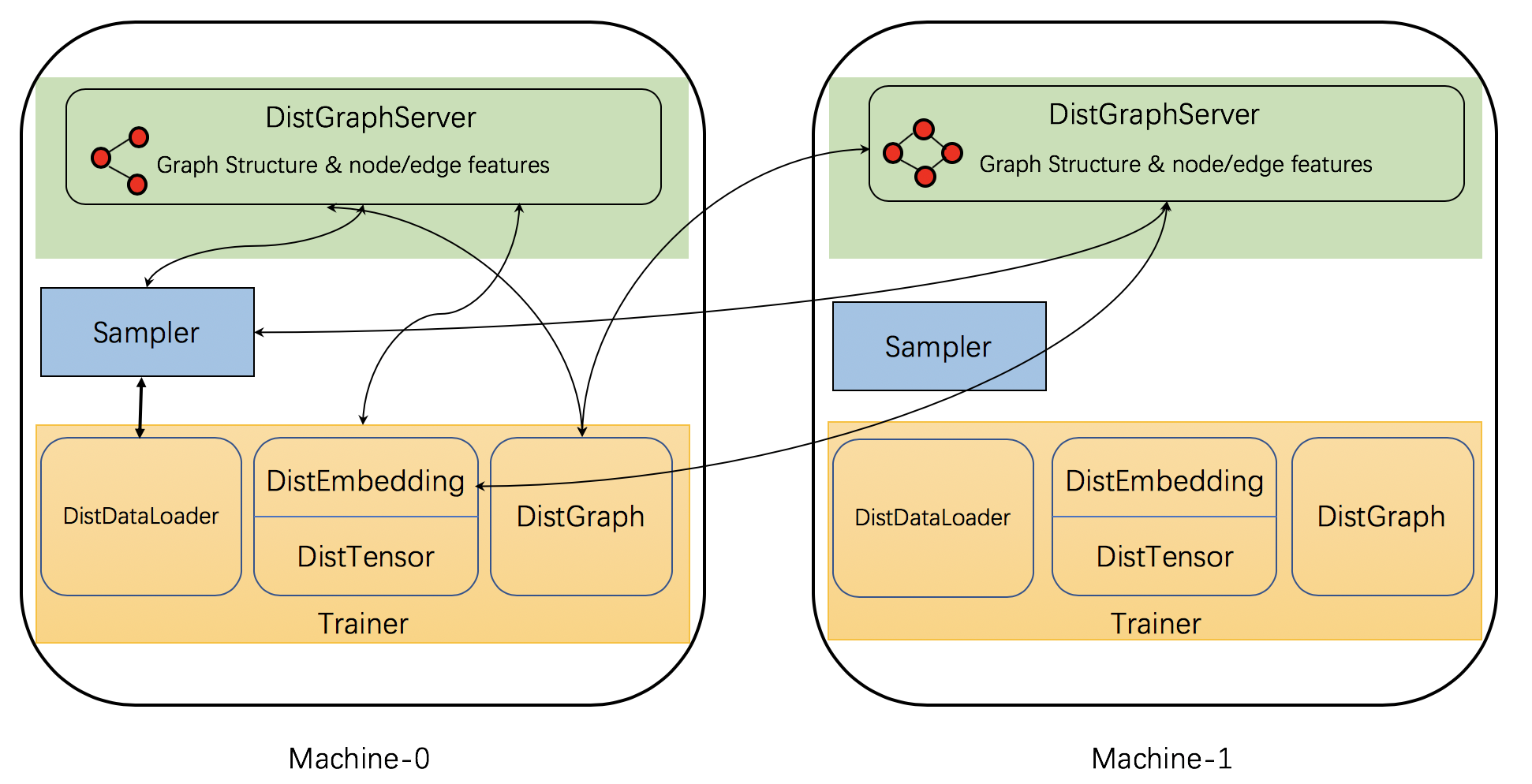
특히, DGL의 분산 학습은 3가지 종류의 프로세스들을 갖는다: 서버, 샘플러, 그리고 트레이너
서버 프로세스는 그래프 파티션(그래프 구조와 노드/에지 피처를 포함)을 저장하고 있는 각 컴퓨터에서 실행된다. 이 서버들은 함께 작동하면서 그래프 데이터를 트레이너에게 제공한다. 한 컴퓨터는 여러 서버 프로세스들을 동시에 수행하면서 연산과 네트워크 통신을 병렬화 한다.
샘플러 프로세스들은 서버들과 상호작용을 하면서, 학습에 사용될 미니-배치를 만들기 위해서 노드와 에지를 샘플링한다.
트레이너들은 서버들과 상호작용을 하기 위한 여러 클래스를 포함하고 있다. 파티션된 그래프 데이터를 접근하기 위한
DistGraph, 노드/에지의 피쳐/임베딩을 접근하기 위한DistEmbedding와DistTensor를 갖는다. 미니-배치를 얻기 위해서 샘플러와 상호작용을 하는DistDataLoader가 있다.
분산 컴포넌드들을 염두해두고, 이 절의 나머지에서는 다음과 같은 분산 컴포넌트들을 다룬다.