Model overview¶
We developed DGL with a broad range of applications in mind. Building state-of-art models forces us to think hard on the most common and useful APIs, learn the hard lessons, and push the system design.
We have prototyped altogether 10 different models, all of them are ready to run out-of-box and some of them are very new graph-based algorithms. In most of the cases, they demonstrate the performance, flexibility, and expressiveness of DGL. For where we still fall in short, these exercises point to future directions.
We categorize the models below, providing links to the original code and tutorial when appropriate. As will become apparent, these models stress the use of different DGL APIs.
Graph Neural Network and its variant¶
- GCN [paper] [tutorial] [Pytorch code] [MXNet code]: this is the vanilla GCN. The tutorial covers the basic uses of DGL APIs.
- GAT [paper] [tutorial] [Pytorch code] [MXNet code]: the key extension of GAT w.r.t vanilla GCN is deploying multi-head attention among neighborhood of a node, thus greatly enhances the capacity and expressiveness of the model.
- R-GCN [paper] [tutorial] [Pytorch code] [MXNet code]: the key difference of RGNN is to allow multi-edges among two entities of a graph, and edges with distinct relationships are encoded differently. This is an interesting extension of GCN that can have a lot of applications of its own.
- LGNN [paper] [tutorial] [Pytorch code]: this model focuses on community detection by inspecting graph structures. It uses representations of both the original graph and its line-graph companion. In addition to demonstrate how an algorithm can harness multiple graphs, our implementation shows how one can judiciously mix vanilla tensor operation, sparse-matrix tensor operations, along with message-passing with DGL.
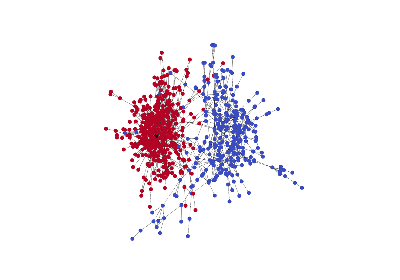
- SSE [paper] [tutorial] [MXNet code]: the emphasize here is giant graph that cannot fit comfortably on one GPU card. SSE is an example to illustrate the co-design of both algorithm and system: sampling to guarantee asymptotic convergence while lowering the complexity, and batching across samples for maximum parallelism.
Dealing with many small graphs¶
- Tree-LSTM [paper] [tutorial] [code]: sentences of natural languages have inherent structures, which are thrown away by treating them simply as sequences. Tree-LSTM is a powerful model that learns the representation by leveraging prior syntactic structures (e.g. parse-tree). The challenge to train it well is that simply by padding a sentence to the maximum length no longer works, since trees of different sentences have different sizes and topologies. DGL solves this problem by throwing the trees into a bigger “container” graph, and use message-passing to explore maximum parallelism. The key API we use is batching.

Generative models¶
- DGMG [paper] [tutorial] [code]: this model belongs to the important family that deals with structural generation. DGMG is interesting because its state-machine approach is the most general. It is also very challenging because, unlike Tree-LSTM, every sample has a dynamic, probability-driven structure that is not available before training. We are able to progressively leverage intra- and inter-graph parallelism to steadily improve the performance.
- JTNN [paper] [code]: unlike DGMG, this paper generates molecular graphs using the framework of variational auto-encoder. Perhaps more interesting is its approach to build structure hierarchically, in the case of molecular, with junction tree as the middle scaffolding.
Old (new) wines in new bottle¶
- Capsule [paper] [tutorial] [code]: this new computer vision model has two key ideas – enhancing the feature representation in a vector form (instead of a scalar) called capsule, and replacing max-pooling with dynamic routing. The idea of dynamic routing is to integrate a lower level capsule to one (or several) of a higher level one with non-parametric message-passing. We show how the later can be nicely implemented with DGL APIs.
- Transformer [paper] [tutorial] [code] and Universal Transformer [paper] [tutorial] [code]: these two models replace RNN with several layers of multi-head attention to encode and discover structures among tokens of a sentence. These attention mechanisms can similarly formulated as graph operations with message-passing.