7.3 Distributed Heterogeneous graph training¶
DGL v0.6.0 provides an experimental support for distributed training on heterogeneous graphs. In DGL, a node or edge in a heterogeneous graph has a unique ID in its own node type or edge type. DGL identifies a node or edge with a tuple: node/edge type and type-wise ID. In distributed training, a node or edge can be identified by a homogeneous ID, in addition to the tuple of node/edge type and type-wise ID. The homogeneous ID is unique regardless of the node type and edge type. DGL arranges nodes and edges so that all nodes of the same type have contiguous homogeneous IDs.
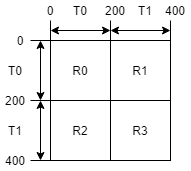
Below is an example adjancency matrix of a heterogeneous graph showing the homogeneous ID assignment. Here, the graph has two types of nodes (T0 and T1 ), and four types of edges (R0, R1, R2, R3 ). There are a total of 400 nodes in the graph and each type has 200 nodes. Nodes of T0 have IDs in [0,200), while nodes of T1 have IDs in [200, 400). In this example, if we use a tuple to identify the nodes, nodes of T0 are identified as (T0, type-wise ID), where type-wise ID falls in [0, 200); nodes of T1 are identified as (T1, type-wise ID), where type-wise ID also falls in [0, 200).
7.3.1 Access distributed graph data¶
For distributed training, DistGraph supports the heterogeneous graph API
in DGLGraph. Below shows an example of getting node data of T0 on some nodes
by using type-wise node IDs. When accessing data in DistGraph, a user
needs to use type-wise IDs and corresponding node types or edge types.
import dgl
g = dgl.distributed.DistGraph('graph_name', part_config='data/graph_name.json')
feat = g.nodes['T0'].data['feat'][type_wise_ids]
A user can create distributed tensors and distributed embeddings for a particular node type or
edge type. Distributed tensors and embeddings are split and stored in multiple machines. To create
one, a user needs to specify how it is partitioned with PartitionPolicy.
By default, DGL chooses the right partition policy based on the size of the first dimension.
However, if multiple node types or edge types have the same number of nodes or edges, DGL cannot
determine the partition policy automatically. A user needs to explicitly specify the partition policy.
Below shows an example of creating a distributed tensor for node type T0 by using the partition policy
for T0 and store it as node data of T0.
g.nodes['T0'].data['feat1'] = dgl.distributed.DistTensor((g.number_of_nodes('T0'), 1), th.float32, 'feat1',
part_policy=g.get_node_partition_policy('T0'))
The partition policies used for creating distributed tensors and embeddings are initialized when a heterogeneous graph is loaded into the graph server. A user cannot create a new partition policy at runtime. Therefore, a user can only create distributed tensors or embeddings for a node type or edge type. Accessing distributed tensors and embeddings also requires type-wise IDs.
7.3.2 Distributed sampling¶
DGL v0.6 uses homogeneous IDs in distributed sampling. Note: this may change in the future release. DGL provides four APIs to convert node IDs and edge IDs between the homogeneous IDs and type-wise IDs:
map_to_per_ntype(): convert a homogeneous node ID to type-wise ID and node type ID.map_to_per_etype(): convert a homogeneous edge ID to type-wise ID and edge type ID.map_to_homo_nid(): convert type-wise ID and node type to a homogeneous node ID.map_to_homo_eid(): convert type-wise ID and edge type to a homogeneous edge ID.
Below shows an example of sampling a subgraph with sample_neighbors() from a heterogeneous graph
with a node type called paper. It first converts type-wise node IDs to homogeneous node IDs. After sampling a subgraph
from the seed nodes, it converts homogeneous node IDs and edge IDs to type-wise IDs and also stores type IDs as node data
and edge data.
gpb = g.get_partition_book()
# We need to map the type-wise node IDs to homogeneous IDs.
cur = gpb.map_to_homo_nid(seeds, 'paper')
# For a heterogeneous input graph, the returned frontier is stored in
# the homogeneous graph format.
frontier = dgl.distributed.sample_neighbors(g, cur, fanout, replace=False)
block = dgl.to_block(frontier, cur)
cur = block.srcdata[dgl.NID]
block.edata[dgl.EID] = frontier.edata[dgl.EID]
# Map the homogeneous edge Ids to their edge type.
block.edata[dgl.ETYPE], block.edata[dgl.EID] = gpb.map_to_per_etype(block.edata[dgl.EID])
# Map the homogeneous node Ids to their node types and per-type Ids.
block.srcdata[dgl.NTYPE], block.srcdata[dgl.NID] = gpb.map_to_per_ntype(block.srcdata[dgl.NID])
block.dstdata[dgl.NTYPE], block.dstdata[dgl.NID] = gpb.map_to_per_ntype(block.dstdata[dgl.NID])
From node/edge type IDs, a user can retrieve node/edge types. For example, g.ntypes[node_type_id]. With node/edge types and type-wise IDs, a user can retrieve node/edge data from DistGraph for mini-batch computation.