5.4 그래프 분류¶
데이터가 커다란 하나의 그래프가 아닌 여러 그래프로 구성된 경우도 종종 있다. 예를 들면, 사람들의 커뮤니티의 여러 종류 목록 같은 것을 들 수 있다. 같은 커뮤니티에 있는 사람들의 친목 관계를 그래프로 특징을 지어본다면, 분류할 수 있는 그래프들의 리스트를 만들 수 있다. 이 상황에서 그래프 분류 모델을 이용해서 커뮤니티의 종류를 구별해볼 수 있다.
개요¶
그래프 분류가 노드 분류나 링크 예측 문제와 주요 차이점은 예측 결과가 전체 입력 그래프의 특성을 나타낸다는 것이다. 이전 문제들과 똑같이 노드들이나 에지들에 대해서 메시지 전달을 수행하지만, 그래프 수준의 representation을 찾아내야한다.
그래프 분류 파이프라인은 다음과 같다:
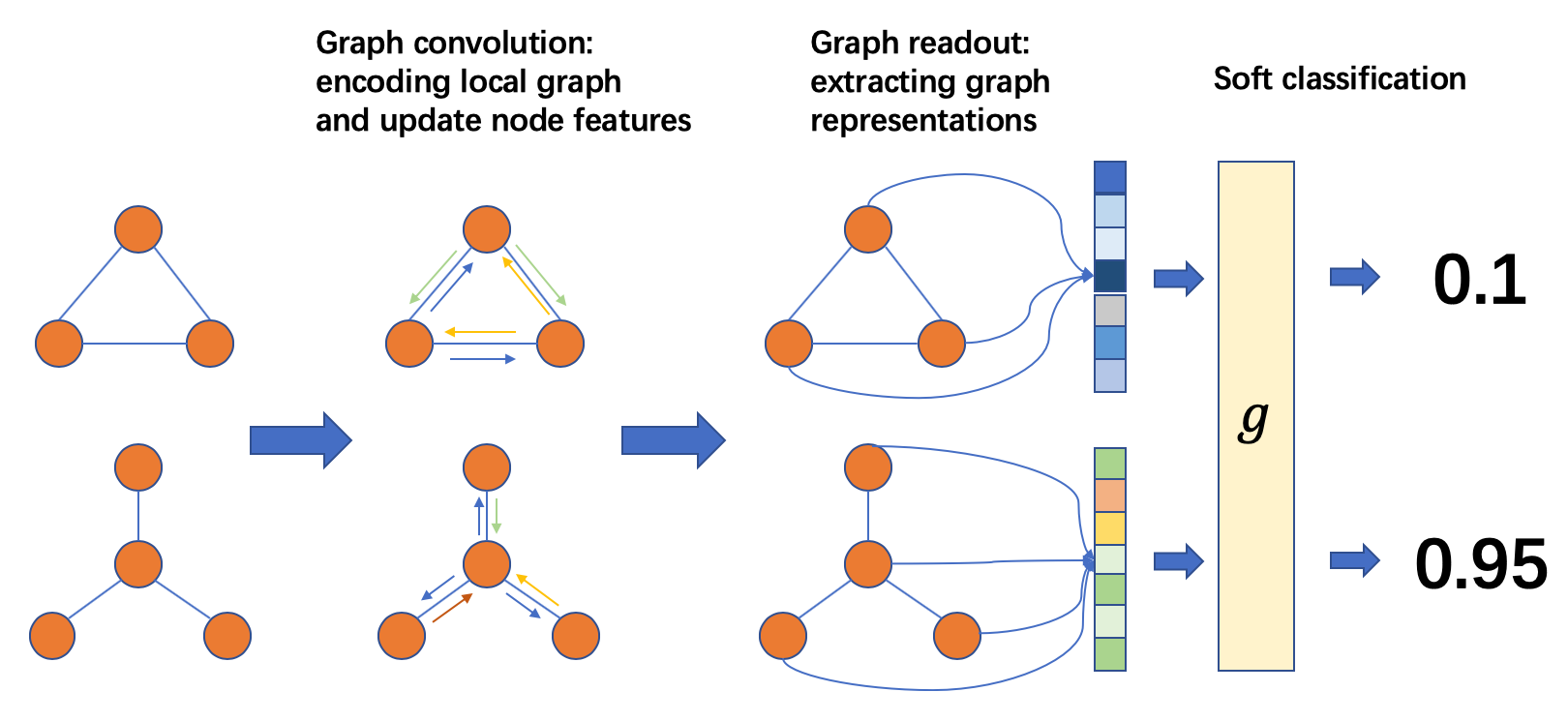
그래프 분류 프로세스¶
일반적인 방법은 (왼쪽부터 오른쪽으로 진행):
그래프들의 배치를 준비한다
그래프들의 배치에 메시지 전달을 수행해서 노드/에지 피쳐를 업데이트한다
노드/에지 피쳐들을 모두 합쳐서 그래프 수준의 representation들을 만든다
그래프 수준의 representation들을 사용해서 그래프들을 분류한다
그래프들의 배치(batch)¶
보통의 경우 그래프 분류 문제는 많은 수의 그래프를 사용해서 학습하기 때문에, 모델을 학습할 때 그래프를 한개씩 사용하는 것은 굉장히 비효율적이다. 일반적 딥러닝에서 사용되는 미니-배치 학습의 아이디어를 발려와서, 그래프들의 배치를 만들어서 한번의 학습 이터레이션에 사용하는 것이 가능하다.
DGL는 그래프들의 리스트로부터 하나의 배치 그래프(batched graph)를 생성할 수 있다. 단순하게, 이 배치 그래프는 원래의 작은 그래프들을 연결하는 컴포넌트를 가지고 있는 하나의 큰 그래프로 사용된다.
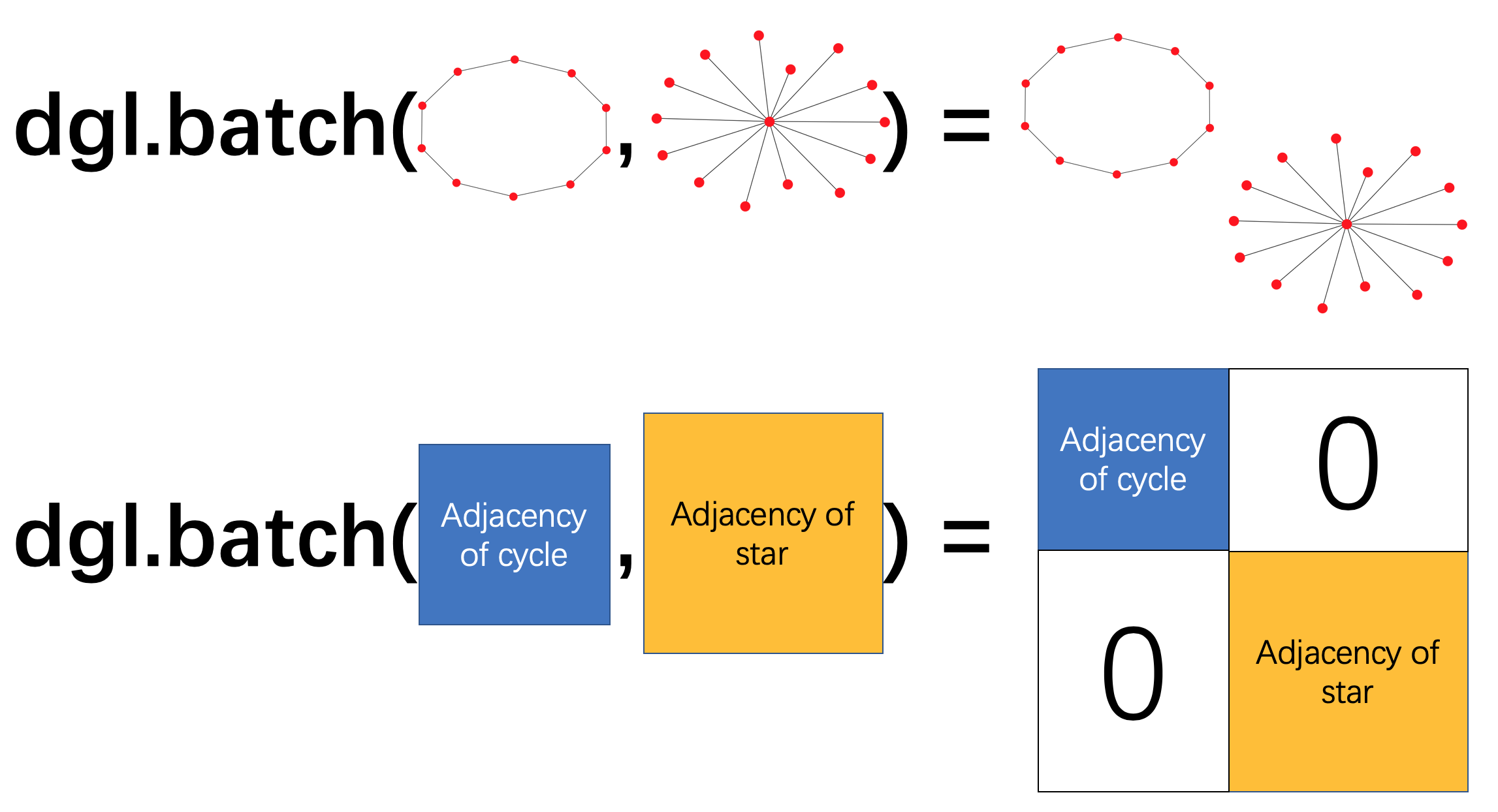
배치 그래프(Batched Graph)¶
다음 코드 예제는 그래프들의 목록에 dgl.batch() 를 호출한다. 배치 그래프는 하나의 그래프이자, 그 리스트에 대한 정보를 담고 있다.
import dgl
import torch as th
g1 = dgl.graph((th.tensor([0, 1, 2]), th.tensor([1, 2, 3])))
g2 = dgl.graph((th.tensor([0, 0, 0, 1]), th.tensor([0, 1, 2, 0])))
bg = dgl.batch([g1, g2])
bg
# Graph(num_nodes=7, num_edges=7,
# ndata_schemes={}
# edata_schemes={})
bg.batch_size
# 2
bg.batch_num_nodes()
# tensor([4, 3])
bg.batch_num_edges()
# tensor([3, 4])
bg.edges()
# (tensor([0, 1, 2, 4, 4, 4, 5], tensor([1, 2, 3, 4, 5, 6, 4]))
대부분의 DGL 변환 함수들은 배치 정보를 버린다는 점을 주의하자. 이 정보를 유지하기 위해서, 변환된 그래프에 dgl.DGLGraph.set_batch_num_nodes() 와 dgl.DGLGraph.set_batch_num_edges() 를 사용한다.
그래프 리드아웃(readout)¶
모든 그래프는 노드와 에지의 피쳐들과 더불어 유일한 구조를 지니고 있다. 하나의 예측을 만들어내기 위해서, 보통은 아마도 풍부한 정보들을 합치고 요약한다. 이런 종류의 연산을 리드아웃(readout) 이라고 부른다. 흔히 쓰이는 리드아웃 연산들은 모든 노드 또는 에지 피쳐들에 대한 합(summation), 평균, 최대 또는 최소들이 있다.
그래프 \(g\) 에 대해서, 평균 노드 피처 리드아웃은 아래와 같이 정의된다.
여기서 \(h_g\) 는 \(g\) 에 대한 representation이고, \(\mathcal{V}\) 는 \(g\) 의 노드들의 집합, 그리고 \(h_v\) 는 노드 \(v\) 의 피쳐이다.
DGL은 많이 쓰이는 리드아웃 연산들을 빌드인 함수로 지원한다. 예를 들어, dgl.mean_nodes() 는 위의 리드아웃 연산을 구현하고 있다.
\(h_g\) 가 구해진 후, 이를 MLP 레이어에 전달해서 분류 결과를 얻는다.
뉴럴 네트워크 모델 작성하기¶
모델에 대한 입력은 노드와 에지의 피쳐들 갖는 배치 그래프이다.
배치 그래프에 연산하기¶
첫째로, 배치 그래프에 있는 그래프들을 완전히 분리되어 있다. 즉, 두 그래들 사이에 에지가 존재하지 않는다. 이런 멋진 성질 덕에, 모든 메시지 전달 함수는 같은 결과를 만들어낸다. (즉 그래프 간의 간섭이 없다)
두번째로, 배치 그래프에 대한 리드아웃 함수는 각 그래프에 별도록 수행된다. 배치 크기가 \(B\) 이고 협쳐진 피쳐(aggregated feature)의 차원이 \(D\) 인 경우, 리드아웃 결과의 shape은 \((B, D)\) 가 된다.
import dgl
import torch
g1 = dgl.graph(([0, 1], [1, 0]))
g1.ndata['h'] = torch.tensor([1., 2.])
g2 = dgl.graph(([0, 1], [1, 2]))
g2.ndata['h'] = torch.tensor([1., 2., 3.])
dgl.readout_nodes(g1, 'h')
# tensor([3.]) # 1 + 2
bg = dgl.batch([g1, g2])
dgl.readout_nodes(bg, 'h')
# tensor([3., 6.]) # [1 + 2, 1 + 2 + 3]
마지막으로, 배치 그래프의 각 노드/에치 피쳐는 모든 그래프의 노드와 에지 피쳐들을 순서대로 연결해서 얻는다.
bg.ndata['h']
# tensor([1., 2., 1., 2., 3.])
모델 정의하기¶
위 연산 규칙을 염두해서, 모델을 다음과 같이 정의한다.
import dgl.nn.pytorch as dglnn
import torch.nn as nn
class Classifier(nn.Module):
def __init__(self, in_dim, hidden_dim, n_classes):
super(Classifier, self).__init__()
self.conv1 = dglnn.GraphConv(in_dim, hidden_dim)
self.conv2 = dglnn.GraphConv(hidden_dim, hidden_dim)
self.classify = nn.Linear(hidden_dim, n_classes)
def forward(self, g, h):
# Apply graph convolution and activation.
h = F.relu(self.conv1(g, h))
h = F.relu(self.conv2(g, h))
with g.local_scope():
g.ndata['h'] = h
# Calculate graph representation by average readout.
hg = dgl.mean_nodes(g, 'h')
return self.classify(hg)
학습 룹¶
데이터 로딩¶
모델이 정의되었다면, 학습을 시작할 수 있다. 그래프 분류는 커다란 그래프 한개가 아니라 상대적으로 작은 그래프를 많이 다루기 때문에, 복잡한 그래프 샘플링 알고리즘을 사용하지 않고 그래프들의 stochastic 미니-배치를 사용해서 효과적으로 학습을 수행할 수 있다.
4장: 그래프 데이터 파이프라인 에서 소개한 그래프 분류 데이터셋을 사용하자.
import dgl.data
dataset = dgl.data.GINDataset('MUTAG', False)
그래프 분류 데이터셋의 각 아이템은 한개의 그래프와 그 그래프의 레이블 쌍이다. 데이터 로딩 프로세스를 빠르게 하기 위해서 GraphDataLoader의 장점을 사용해 그래프들의 데이터셋을 미니-배치 단위로 iterate한다.
from dgl.dataloading import GraphDataLoader
dataloader = GraphDataLoader(
dataset,
batch_size=1024,
drop_last=False,
shuffle=True)
학습 룹은 데이터로더를 iterate하면서 모델을 업데이트하는 것일 뿐이다.
import torch.nn.functional as F
# Only an example, 7 is the input feature size
model = Classifier(7, 20, 5)
opt = torch.optim.Adam(model.parameters())
for epoch in range(20):
for batched_graph, labels in dataloader:
feats = batched_graph.ndata['attr']
logits = model(batched_graph, feats)
loss = F.cross_entropy(logits, labels)
opt.zero_grad()
loss.backward()
opt.step()
DGL’s GIN example 의 end-to-end 그래프 분류 예를 참고하자. 이 학습 룹은 main.py 의 train 함수안에 있다. 모델의 구현은 gin.py 에 있고, dgl.nn.pytorch.GINConv (MXNet 및 Tensorflow 버전도 있음)와 같은 컴포넌트들과 graph convolution layer와 배치 normalization 등이 적용되어 있다.
Heterogeneous 그래프¶
Heterogeneous 그래프들에 대한 그래프 분류는 homogeneous 그래프의 경우와는 약간 차이가 있다. Heterogeneous 그래프와 호환되는 graph convolution 모듈에 더해서, 리드아웃 함수에서 다른 종류의 노드들에 대한 aggregate를 해야한다.
다음 코드는 각 노트 타입에 대해서 노드 representation을 평균을 합산하는 예제이다.
class RGCN(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats, rel_names):
super().__init__()
self.conv1 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(in_feats, hid_feats)
for rel in rel_names}, aggregate='sum')
self.conv2 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(hid_feats, out_feats)
for rel in rel_names}, aggregate='sum')
def forward(self, graph, inputs):
# inputs is features of nodes
h = self.conv1(graph, inputs)
h = {k: F.relu(v) for k, v in h.items()}
h = self.conv2(graph, h)
return h
class HeteroClassifier(nn.Module):
def __init__(self, in_dim, hidden_dim, n_classes, rel_names):
super().__init__()
self.rgcn = RGCN(in_dim, hidden_dim, hidden_dim, rel_names)
self.classify = nn.Linear(hidden_dim, n_classes)
def forward(self, g):
h = g.ndata['feat']
h = self.rgcn(g, h)
with g.local_scope():
g.ndata['h'] = h
# Calculate graph representation by average readout.
hg = 0
for ntype in g.ntypes:
hg = hg + dgl.mean_nodes(g, 'h', ntype=ntype)
return self.classify(hg)
나머지 코드는 homegeneous 그래프의 경우와 다르지 않다.
# etypes is the list of edge types as strings.
model = HeteroClassifier(10, 20, 5, etypes)
opt = torch.optim.Adam(model.parameters())
for epoch in range(20):
for batched_graph, labels in dataloader:
logits = model(batched_graph)
loss = F.cross_entropy(logits, labels)
opt.zero_grad()
loss.backward()
opt.step()