7.3 분산 heterogeneous 그래프 학습하기¶
DGL v0.6.0은 heterogeneous 그래프들을 위한 분산 학습을 실험적으로 지원한다. DGL에서 heterogeneous 그래프의 노드와 에지는 그 노드 타입 및 에지 타입에서 고유한 ID를 갖는다. DGL은 노드/에지 타입과 타입별 ID의 tuple을 사용해서 노드 및 에지를 지정한다. 분산 학습에서는 노드/에지 타입과 타입별 ID의 tuple과 더불어서 노드 또는 에지는 homogeneous ID를 통해서 지정될 수 있다. Homogeneous ID는 노드 타입이나 에지 타입과 관련없이 고유하다. DGL은 같은 타입의 모든 노드들이 연속된 homogeneous ID값들을 갖도록 노드와 에지를 정렬한다.
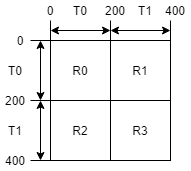
아래 그림은 homegeneous ID 할당을 보여주는 heterogeneous 그래프의 adjacency matrix이다. 여기서 그래프틑 두가지 노드 타입( T0 와 T1 )을, 네가지 에지 타입(R0 , R1 , R2 , R3 )를 갖는다. 그래프는 총 400개의 노드를 갖고, 각 타입은 200개 노드를 갖는다. T0 의 노드들은 [0,200)의 ID를 갖고, T1 의 노드들은 [200, 400)의 ID 값을 갖는다. 여기서 만약 tuple을 사용해서 노드를 구분한다면, T0 의 노드들은 (T0, type-wise ID)로 지정될 수 있다. 여기서 type-wise ID는 [0,200)에 속한다; T1 의 노드들은 (T1, type-wise ID)으로 지정되고, type-wise ID는 [0, 200)에 속한다.
7.3.1 분산 그래프 데이터 접근하기¶
분산 학습을 위해 DistGraph 은 DGLGraph 에서 heterogeneous 그래프 API를 지원한다. 아래 코드는 T0 의 노드 데이터를 type-wise 노드 ID를 사용해서 얻는 것을 보여준다. DGLGraph 의 데이터를 접근할 때, 사용자는 type-wise ID와 연관된 노드 타입 또는 에지 타입을 사용해야 한다.
import dgl
g = dgl.distributed.DistGraph('graph_name', part_config='data/graph_name.json')
feat = g.nodes['T0'].data['feat'][type_wise_ids]
사용자는 특정 노드 타입 또는 에지 타입에 대한 분산 텐서 및 분산 임베딩을 생성할 수 있다. 분산 텐서들과 분산 임베딩들은 여러 머신에 나눠져서 저장된다. 만들 때는 PartitionPolicy 로 파티션을 어떻게 할지를 명시해야 한다. 기본 설정으로 DGL은 첫 차원 값의 크기를 기반으로 적절한 파티션 정책을 선택한다. 하지만, 다중 노드 타입 또는 에지 타입이 같은 수의 노드 또는 에지를 갖는 다면, DGL은 파티션 정책을 자동으로 결정할 수 없고, 사용자는 직접 파티션 정책을 지정해야 한다. 아래 코드는 노드 타입 T0 의 분산 텐서를 T0 를 위한 파티션 정책을 사용해서 생성하고, 이를 T0 의 노드 데이터로 저장한다.
g.nodes['T0'].data['feat1'] = dgl.distributed.DistTensor((g.number_of_nodes('T0'), 1), th.float32, 'feat1',
part_policy=g.get_node_partition_policy('T0'))
분산 텐서 및 분산 임베딩을 만들기 위한 파티션 정책은 heterogeneous 그래프가 그래프 서버에 로드될 때 초기화된다. 사용자는 새로운 파티션 정책을 실행 중에 생성할 수 없다. 따라서, 사용자는 노드 타입 이나 에지 타입에 대한 분산 텐서 또는 분산 임베딩 만을 만들 수 있다.
7.3.2 분산 샘플링¶
DGL v0.6은 분산 샘플링에서 homogeneous ID를 사용한다. Note: 이는 앞으로 릴리즈에서 바뀔 수도 있다. DGL은 homogeneous ID와 type-wise ID 간에 노드 ID와 에지 ID를 변환하는 네 개의 API를 제공한다.
map_to_per_ntype(): homogeneous 노드 ID를 type-wise ID와 노드 타입 ID로 변환한다.map_to_per_etype(): homogeneous 에지 ID를 type-wise ID와 에지 타입 ID로 변환한다.map_to_homo_nid(): type-wise ID와 노드 타입을 homogeneous 노드 ID로 변환한다.map_to_homo_eid(): type-wise ID와 에지 타입을 homogeneous 에지 ID로 변환한다.
다음 예제는 paper 라는 노드 타입을 갖는 heterogeneous 그래프로부터 sample_neighbors() 를 사용해서 서브 그래프를 샘플링한다. 이는 우선 type-wise 노드 ID들을 homogeneous 노드 ID들로 변환한다. 시드 노드들로 서브 그래프를 샘플링 한 다음, homogeneous 노드 ID들과 에지 ID들을 type-wise ID들로 바꾸고, 타입 ID를 노드 데이터와 에지 데이터에 저장한다.
gpb = g.get_partition_book()
# We need to map the type-wise node IDs to homogeneous IDs.
cur = gpb.map_to_homo_nid(seeds, 'paper')
# For a heterogeneous input graph, the returned frontier is stored in
# the homogeneous graph format.
frontier = dgl.distributed.sample_neighbors(g, cur, fanout, replace=False)
block = dgl.to_block(frontier, cur)
cur = block.srcdata[dgl.NID]
block.edata[dgl.EID] = frontier.edata[dgl.EID]
# Map the homogeneous edge Ids to their edge type.
block.edata[dgl.ETYPE], block.edata[dgl.EID] = gpb.map_to_per_etype(block.edata[dgl.EID])
# Map the homogeneous node Ids to their node types and per-type Ids.
block.srcdata[dgl.NTYPE], block.srcdata[dgl.NID] = gpb.map_to_per_ntype(block.srcdata[dgl.NID])
block.dstdata[dgl.NTYPE], block.dstdata[dgl.NID] = gpb.map_to_per_ntype(block.dstdata[dgl.NID])
노드/에지 타입 ID를 위해서, 사용자는 노드/에지 타입을 검색할 수 있다. 예를 들어, g.ntypes[node_type_id] . 노드/에지 타입들과 type-wise ID들을 사용해서, 사용자는 미니배치 계산을 위해서 DistGraph 로부터 노드/에지 데이터를 검색할 수 있다.