Note
Click here to download the full example code
Single Machine Multi-GPU Minibatch Graph Classification¶
In this tutorial, you will learn how to use multiple GPUs in training a graph neural network (GNN) for graph classification. This tutorial assumes knowledge in GNNs for graph classification and we recommend you to check Training a GNN for Graph Classification otherwise.
(Time estimate: 8 minutes)
To use a single GPU in training a GNN, we need to put the model, graph(s), and other tensors (e.g. labels) on the same GPU:
import torch
# Use the first GPU
device = torch.device("cuda:0")
model = model.to(device)
graph = graph.to(device)
labels = labels.to(device)
The node and edge features in the graphs, if any, will also be on the GPU. After that, the forward computation, backward computation and parameter update will take place on the GPU. For graph classification, this repeats for each minibatch gradient descent.
Using multiple GPUs allows performing more computation per unit of time. It is like having a team work together, where each GPU is a team member. We need to distribute the computation workload across GPUs and let them synchronize the efforts regularly. PyTorch provides convenient APIs for this task with multiple processes, one per GPU, and we can use them in conjunction with DGL.
Intuitively, we can distribute the workload along the dimension of data. This
allows multiple GPUs to perform the forward and backward computation of
multiple gradient descents in parallel. To distribute a dataset across
multiple GPUs, we need to partition it into multiple mutually exclusive
subsets of a similar size, one per GPU. We need to repeat the random
partition every epoch to guarantee randomness. We can use
GraphDataLoader(), which wraps some PyTorch
APIs and does the job for graph classification in data loading.
Once all GPUs have finished the backward computation for its minibatch,
we need to synchronize the model parameter update across them. Specifically,
this involves collecting gradients from all GPUs, averaging them and updating
the model parameters on each GPU. We can wrap a PyTorch model with
DistributedDataParallel() so that the model
parameter update will invoke gradient synchronization first under the hood.
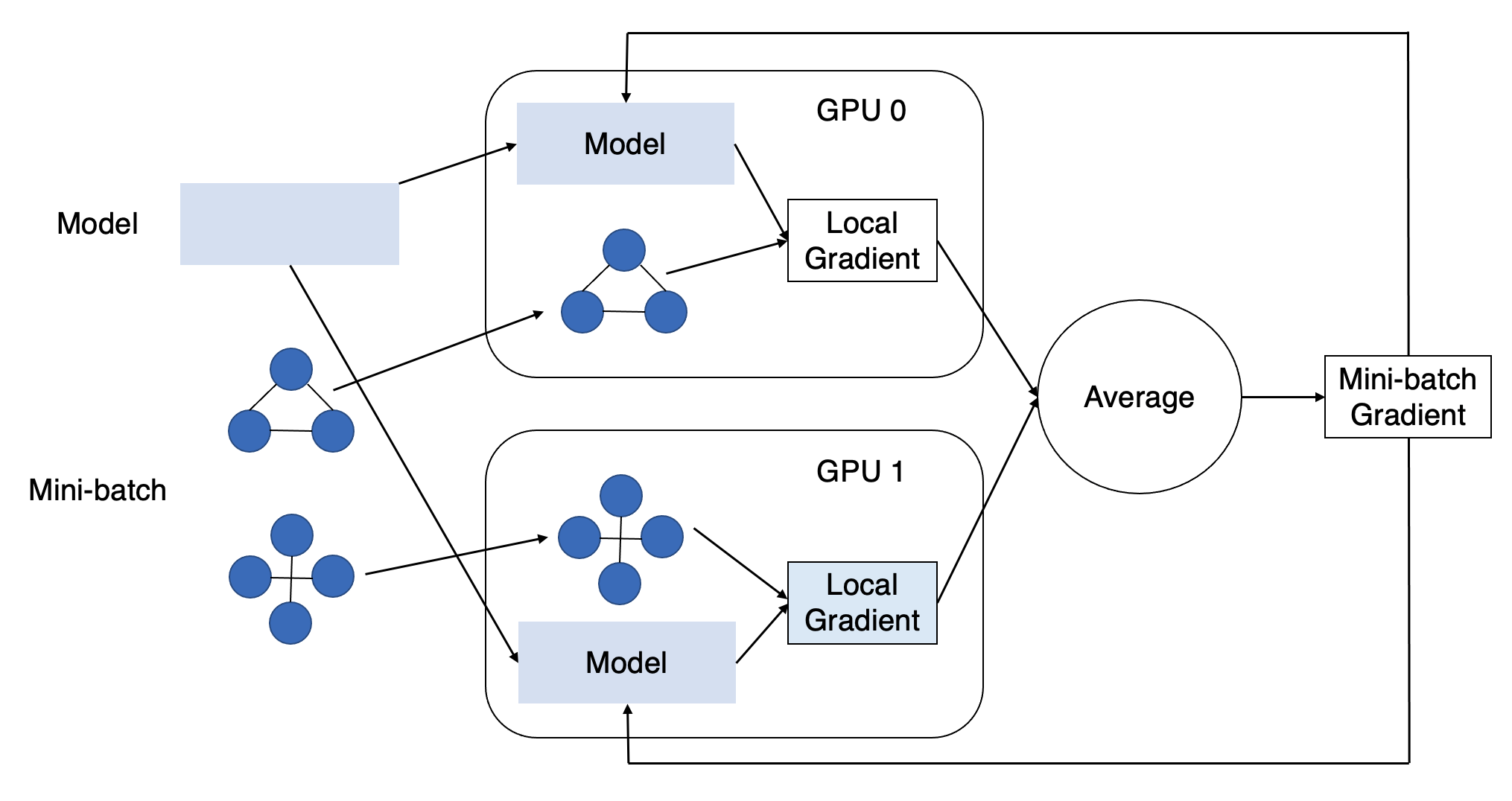
That’s the core behind this tutorial. We will explore it more in detail with a complete example below.
Note
See this tutorial
from PyTorch for general multi-GPU training with DistributedDataParallel.
Distributed Process Group Initialization¶
For communication between multiple processes in multi-gpu training, we need to start the distributed backend at the beginning of each process. We use world_size to refer to the number of processes and rank to refer to the process ID, which should be an integer from 0 to world_size - 1.
Data Loader Preparation¶
We split the dataset into training, validation and test subsets. In dataset
splitting, we need to use a same random seed across processes to ensure a
same split. We follow the common practice to train with multiple GPUs and
evaluate with a single GPU, thus only set use_ddp to True in the
GraphDataLoader() for the training set, where
ddp stands for DistributedDataParallel().
from dgl.data import split_dataset
from dgl.dataloading import GraphDataLoader
def get_dataloaders(dataset, seed, batch_size=32):
# Use a 80:10:10 train-val-test split
train_set, val_set, test_set = split_dataset(dataset,
frac_list=[0.8, 0.1, 0.1],
shuffle=True,
random_state=seed)
train_loader = GraphDataLoader(train_set, use_ddp=True, batch_size=batch_size, shuffle=True)
val_loader = GraphDataLoader(val_set, batch_size=batch_size)
test_loader = GraphDataLoader(test_set, batch_size=batch_size)
return train_loader, val_loader, test_loader
Model Initialization¶
For this tutorial, we use a simplified Graph Isomorphism Network (GIN).
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GINConv, SumPooling
class GIN(nn.Module):
def __init__(self, input_size=1, num_classes=2):
super(GIN, self).__init__()
self.conv1 = GINConv(nn.Linear(input_size, num_classes), aggregator_type='sum')
self.conv2 = GINConv(nn.Linear(num_classes, num_classes), aggregator_type='sum')
self.pool = SumPooling()
def forward(self, g, feats):
feats = self.conv1(g, feats)
feats = F.relu(feats)
feats = self.conv2(g, feats)
return self.pool(g, feats)
To ensure same initial model parameters across processes, we need to set the
same random seed before model initialization. Once we construct a model
instance, we wrap it with DistributedDataParallel().
import torch
from torch.nn.parallel import DistributedDataParallel
def init_model(seed, device):
torch.manual_seed(seed)
model = GIN().to(device)
model = DistributedDataParallel(model, device_ids=[device], output_device=device)
return model
Main Function for Each Process¶
Define the model evaluation function as in the single-GPU setting.
def evaluate(model, dataloader, device):
model.eval()
total = 0
total_correct = 0
for bg, labels in dataloader:
bg = bg.to(device)
labels = labels.to(device)
# Get input node features
feats = bg.ndata.pop('attr')
with torch.no_grad():
pred = model(bg, feats)
_, pred = torch.max(pred, 1)
total += len(labels)
total_correct += (pred == labels).sum().cpu().item()
return 1.0 * total_correct / total
Define the main function for each process.
from torch.optim import Adam
def main(rank, world_size, dataset, seed=0):
init_process_group(world_size, rank)
# Assume the GPU ID to be the same as the process ID
device = torch.device('cuda:{:d}'.format(rank))
torch.cuda.set_device(device)
model = init_model(seed, device)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.01)
train_loader, val_loader, test_loader = get_dataloaders(dataset,
seed)
for epoch in range(5):
model.train()
# The line below ensures all processes use a different
# random ordering in data loading for each epoch.
train_loader.set_epoch(epoch)
total_loss = 0
for bg, labels in train_loader:
bg = bg.to(device)
labels = labels.to(device)
feats = bg.ndata.pop('attr')
pred = model(bg, feats)
loss = criterion(pred, labels)
total_loss += loss.cpu().item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss = total_loss
print('Loss: {:.4f}'.format(loss))
val_acc = evaluate(model, val_loader, device)
print('Val acc: {:.4f}'.format(val_acc))
test_acc = evaluate(model, test_loader, device)
print('Test acc: {:.4f}'.format(test_acc))
dist.destroy_process_group()
Finally we load the dataset and launch the processes.
Note
You will need to use dgl.multiprocessing instead of the Python
multiprocessing package. dgl.multiprocessing is identical to
Python’s built-in multiprocessing except that it handles the
subtleties between forking and multithreading in Python.
if __name__ == '__main__':
import dgl.multiprocessing as mp
from dgl.data import GINDataset
num_gpus = 4
procs = []
dataset = GINDataset(name='IMDBBINARY', self_loop=False)
for rank in range(num_gpus):
p = mp.Process(target=main, args=(rank, num_gpus, dataset))
p.start()
procs.append(p)
for p in procs:
p.join()
# Thumbnail credits: DGL
# sphinx_gallery_thumbnail_path = '_static/blitz_5_graph_classification.png'
Total running time of the script: ( 0 minutes 0.668 seconds)