Note
Click here to download the full example code
Writing GNN Modules for Stochastic GNN Training¶
All GNN modules DGL provides support stochastic GNN training. This tutorial teaches you how to write your own graph neural network module for stochastic GNN training. It assumes that
import os
os.environ["DGLBACKEND"] = "pytorch"
import dgl
import numpy as np
import torch
from ogb.nodeproppred import DglNodePropPredDataset
dataset = DglNodePropPredDataset("ogbn-arxiv")
device = "cpu" # change to 'cuda' for GPU
graph, node_labels = dataset[0]
# Add reverse edges since ogbn-arxiv is unidirectional.
graph = dgl.add_reverse_edges(graph)
graph.ndata["label"] = node_labels[:, 0]
idx_split = dataset.get_idx_split()
train_nids = idx_split["train"]
node_features = graph.ndata["feat"]
sampler = dgl.dataloading.MultiLayerNeighborSampler([4, 4])
train_dataloader = dgl.dataloading.DataLoader(
graph,
train_nids,
sampler,
batch_size=1024,
shuffle=True,
drop_last=False,
num_workers=0,
)
input_nodes, output_nodes, mfgs = next(iter(train_dataloader))
Out:
/home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/checkouts/1.1.x/python/dgl/dataloading/dataloader.py:1150: DGLWarning: Dataloader CPU affinity opt is not enabled, consider switching it on (see enable_cpu_affinity() or CPU best practices for DGL [https://docs.dgl.ai/tutorials/cpu/cpu_best_practises.html])
f"Dataloader CPU affinity opt is not enabled, consider switching it on "
DGL Bipartite Graph Introduction¶
In the previous tutorials, you have seen the concept message flow graph (MFG), where nodes are divided into two parts. It is a kind of (directional) bipartite graph. This section introduces how you can manipulate (directional) bipartite graphs.
You can access the source node features and destination node features via
srcdata and dstdata attributes:
mfg = mfgs[0]
print(mfg.srcdata)
print(mfg.dstdata)
Out:
{'year': tensor([[2004],
[2016],
[2011],
...,
[2010],
[2011],
[2014]]), 'feat': tensor([[ 0.0863, 0.0047, -0.1473, ..., 0.2035, -0.1164, -0.1786],
[-0.0638, -0.0646, -0.3289, ..., 0.0176, -0.0278, -0.2075],
[ 0.0008, 0.1380, -0.2089, ..., 0.1758, 0.1850, -0.1300],
...,
[-0.0610, -0.0225, -0.2093, ..., 0.2072, -0.0461, -0.0808],
[ 0.0038, -0.1325, -0.2102, ..., 0.1164, 0.0267, -0.1949],
[ 0.0493, -0.1923, -0.2374, ..., 0.1949, 0.1038, -0.2153]]), 'label': tensor([ 2, 8, 8, ..., 28, 28, 28]), '_ID': tensor([ 48619, 18894, 158992, ..., 161625, 96298, 1512])}
{'year': tensor([[2004],
[2016],
[2011],
...,
[2012],
[2017],
[2006]]), 'feat': tensor([[ 0.0863, 0.0047, -0.1473, ..., 0.2035, -0.1164, -0.1786],
[-0.0638, -0.0646, -0.3289, ..., 0.0176, -0.0278, -0.2075],
[ 0.0008, 0.1380, -0.2089, ..., 0.1758, 0.1850, -0.1300],
...,
[-0.0795, 0.1066, -0.1990, ..., 0.1197, -0.0439, -0.1757],
[-0.0698, 0.0822, -0.2286, ..., 0.1476, -0.0558, -0.1544],
[-0.0657, 0.1287, -0.2047, ..., 0.0949, -0.2059, -0.1258]]), 'label': tensor([ 2, 8, 8, ..., 28, 28, 28]), '_ID': tensor([ 48619, 18894, 158992, ..., 81606, 111323, 139816])}
It also has num_src_nodes and num_dst_nodes functions to query
how many source nodes and destination nodes exist in the bipartite graph:
print(mfg.num_src_nodes(), mfg.num_dst_nodes())
Out:
12595 4039
You can assign features to srcdata and dstdata just as what you
will do with ndata on the graphs you have seen earlier:
mfg.srcdata["x"] = torch.zeros(mfg.num_src_nodes(), mfg.num_dst_nodes())
dst_feat = mfg.dstdata["feat"]
Also, since the bipartite graphs are constructed by DGL, you can retrieve the source node IDs (i.e. those that are required to compute the output) and destination node IDs (i.e. those whose representations the current GNN layer should compute) as follows.
Out:
(tensor([ 48619, 18894, 158992, ..., 161625, 96298, 1512]), tensor([ 48619, 18894, 158992, ..., 81606, 111323, 139816]))
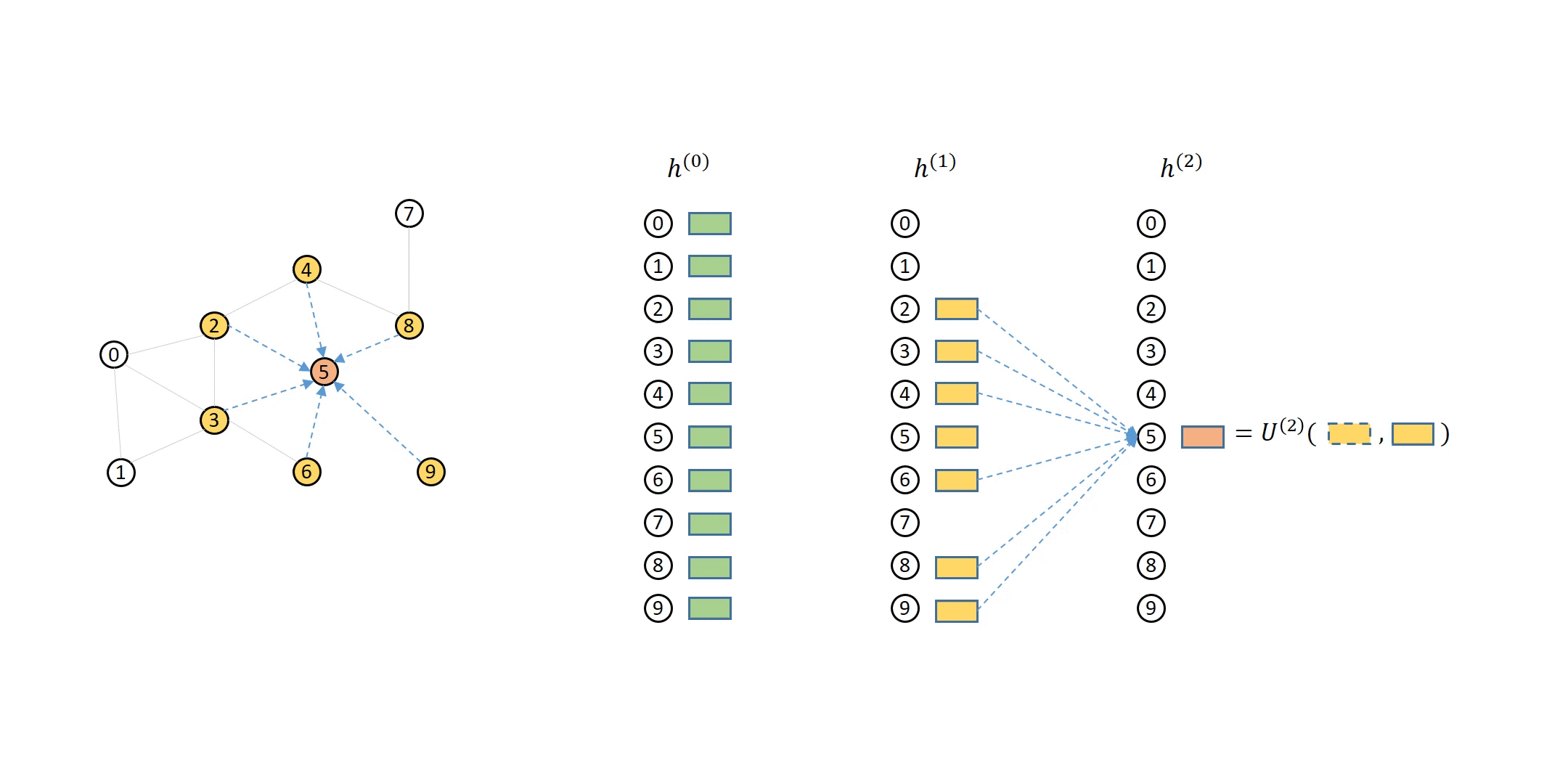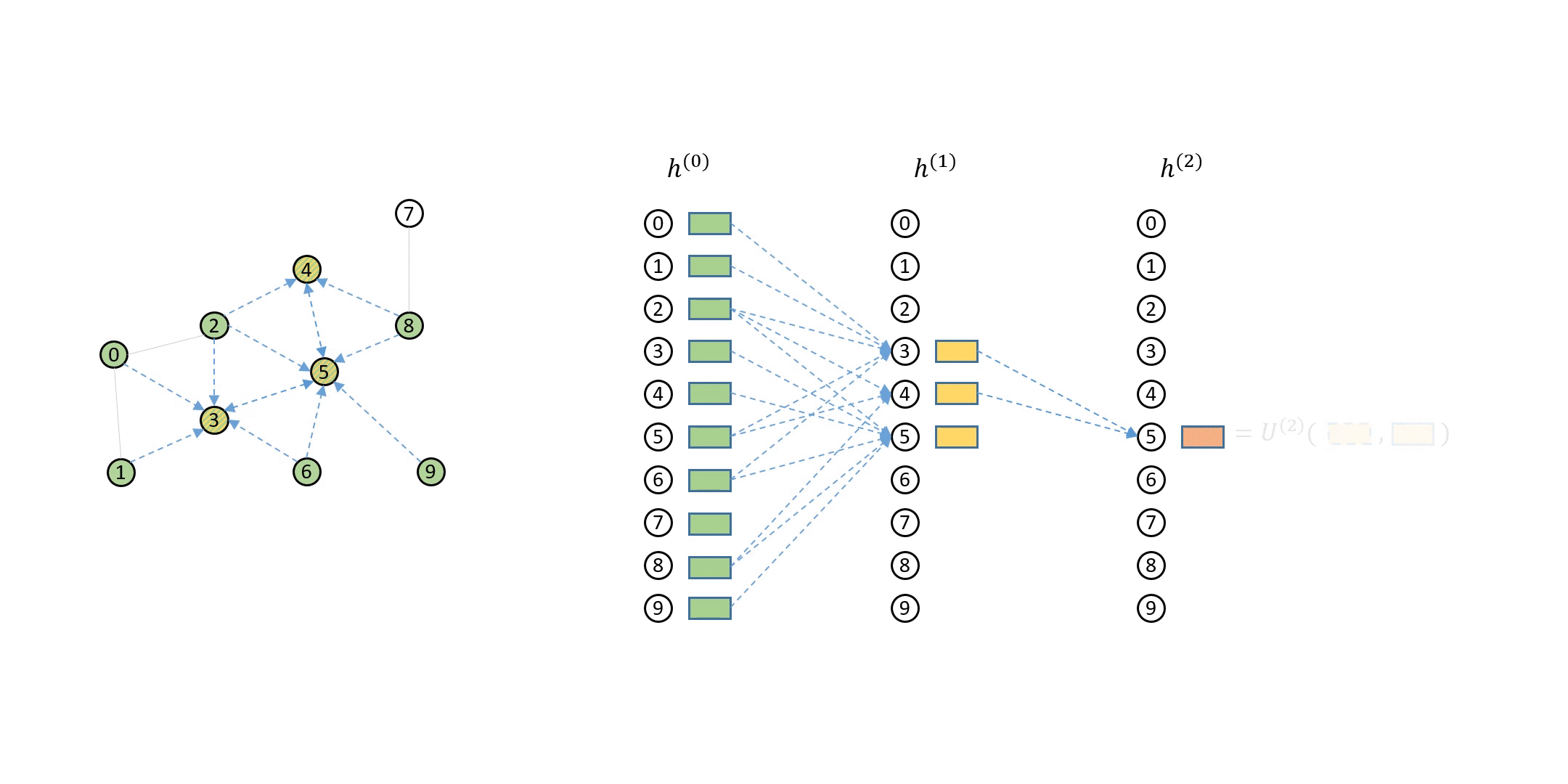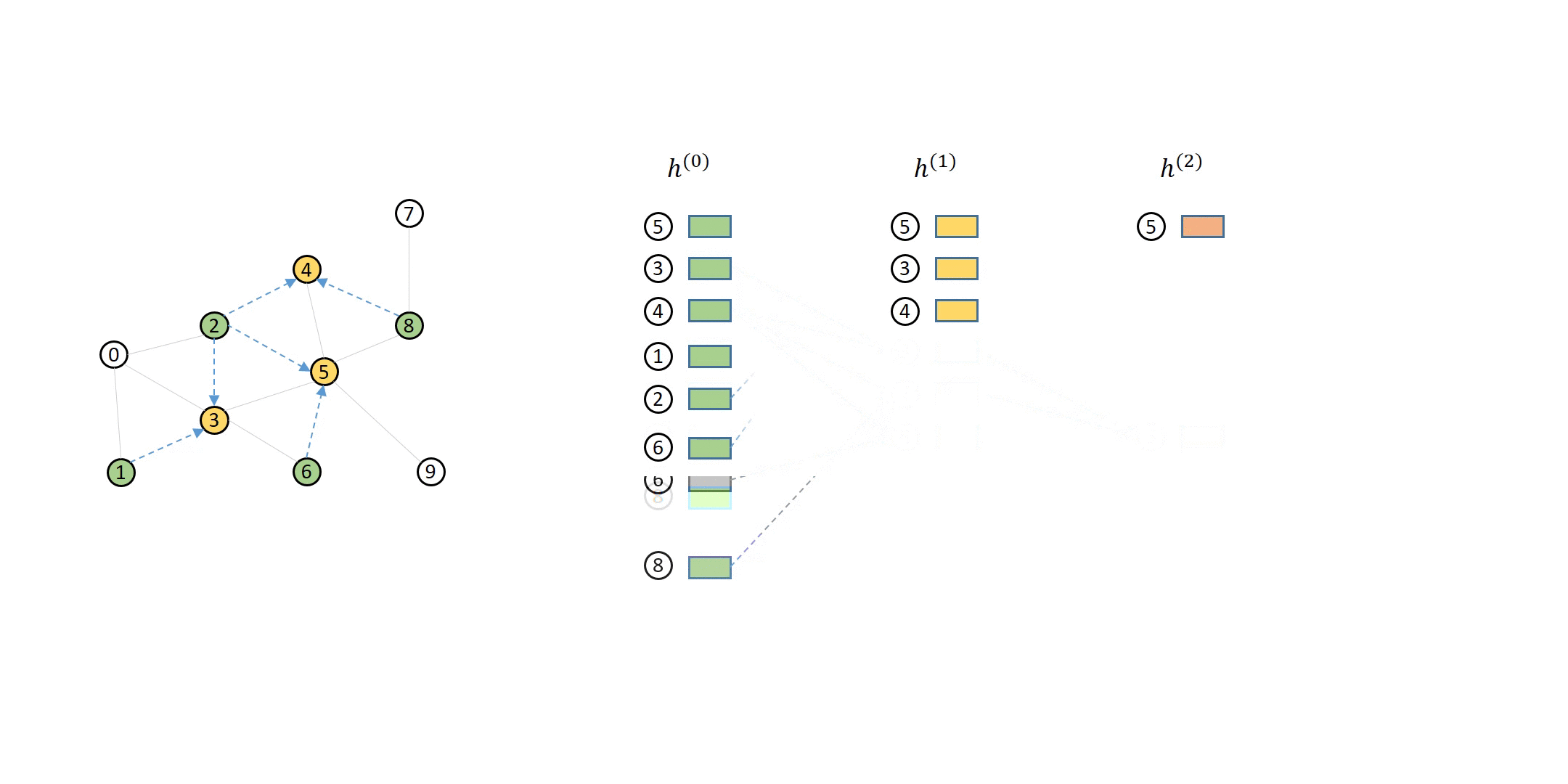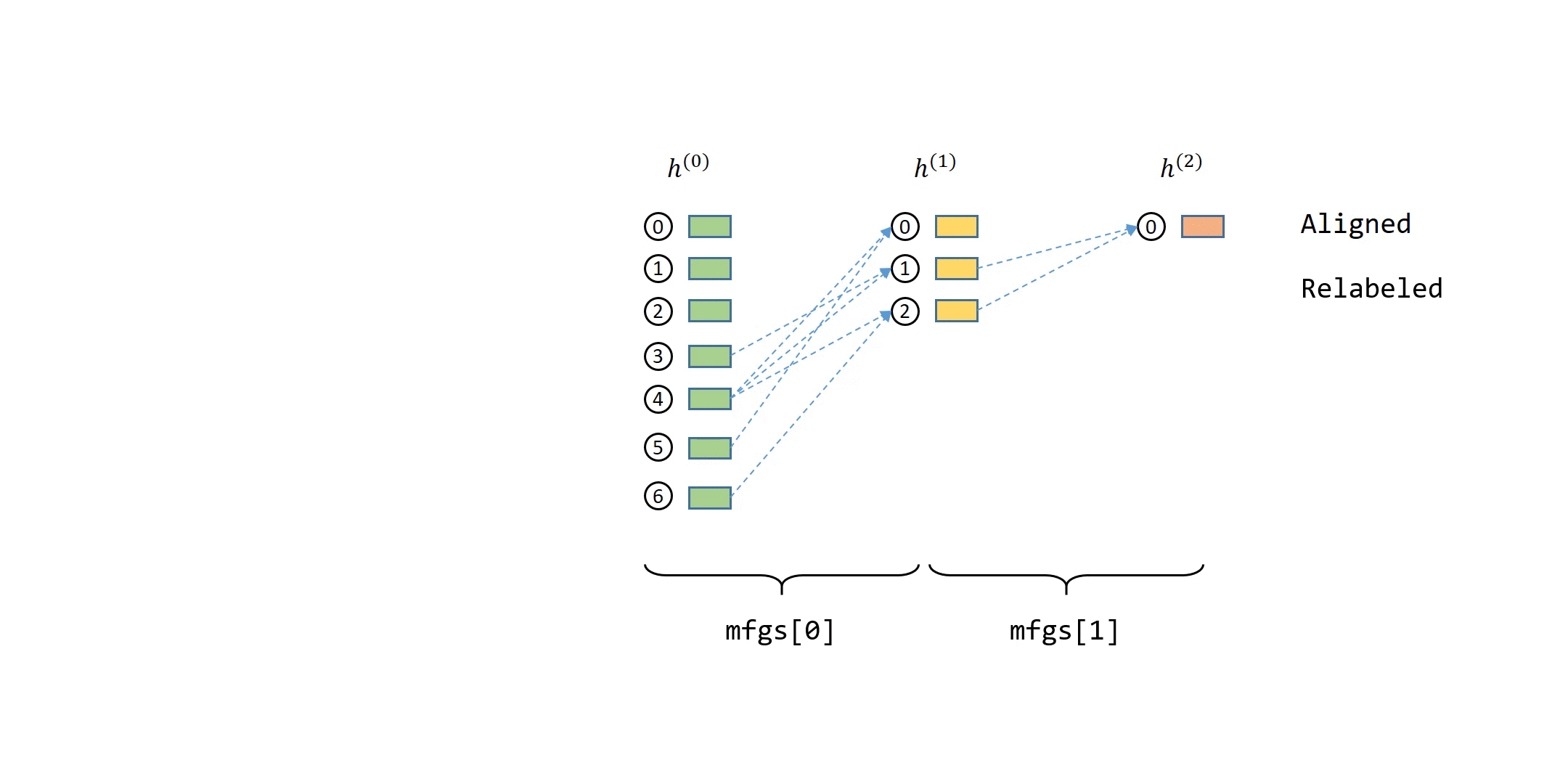
Writing GNN Modules for Bipartite Graphs for Stochastic Training¶
Recall that the MFGs yielded by the DataLoader
have the property that the first few source nodes are
always identical to the destination nodes:
Out:
True
Suppose you have obtained the source node representations \(h_u^{(l-1)}\):
mfg.srcdata["h"] = torch.randn(mfg.num_src_nodes(), 10)
Recall that DGL provides the update_all interface for expressing how to compute messages and how to aggregate them on the nodes that receive them. This concept naturally applies to bipartite graphs like MFGs – message computation happens on the edges between source and destination nodes of the edges, and message aggregation happens on the destination nodes.
For example, suppose the message function copies the source feature (i.e. \(M^{(l)}\left(h_v^{(l-1)}, h_u^{(l-1)}, e_{u\to v}^{(l-1)}\right) = h_v^{(l-1)}\)), and the reduce function averages the received messages. Performing such message passing computation on a bipartite graph is no different than on a full graph:
import dgl.function as fn
mfg.update_all(message_func=fn.copy_u("h", "m"), reduce_func=fn.mean("m", "h"))
m_v = mfg.dstdata["h"]
m_v
Out:
tensor([[-0.0722, 0.0395, -1.0023, ..., 0.4863, 0.1701, -0.1982],
[ 0.5011, 0.1698, 0.4219, ..., -0.3493, 0.5804, -0.4121],
[-0.3380, 0.5033, 0.2379, ..., -0.6563, 0.9205, 0.1379],
...,
[-0.7944, -0.2380, 0.0942, ..., 1.2444, 0.8138, -0.3231],
[ 0.6311, -0.5021, -0.3760, ..., 0.2353, -0.3995, 0.4904],
[ 0.2358, -0.5006, -0.3630, ..., 0.7851, -0.4532, 0.1952]])
Putting them together, you can implement a GraphSAGE convolution for
training with neighbor sampling as follows (the differences to the full graph
counterpart are highlighted with arrows <---)
import torch.nn as nn
import torch.nn.functional as F
import tqdm
class SAGEConv(nn.Module):
"""Graph convolution module used by the GraphSAGE model.
Parameters
----------
in_feat : int
Input feature size.
out_feat : int
Output feature size.
"""
def __init__(self, in_feat, out_feat):
super(SAGEConv, self).__init__()
# A linear submodule for projecting the input and neighbor feature to the output.
self.linear = nn.Linear(in_feat * 2, out_feat)
def forward(self, g, h):
"""Forward computation
Parameters
----------
g : Graph
The input MFG.
h : (Tensor, Tensor)
The feature of source nodes and destination nodes as a pair of Tensors.
"""
with g.local_scope():
h_src, h_dst = h
g.srcdata["h"] = h_src # <---
g.dstdata["h"] = h_dst # <---
# update_all is a message passing API.
g.update_all(fn.copy_u("h", "m"), fn.mean("m", "h_N"))
h_N = g.dstdata["h_N"]
h_total = torch.cat([h_dst, h_N], dim=1) # <---
return self.linear(h_total)
class Model(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(Model, self).__init__()
self.conv1 = SAGEConv(in_feats, h_feats)
self.conv2 = SAGEConv(h_feats, num_classes)
def forward(self, mfgs, x):
h_dst = x[: mfgs[0].num_dst_nodes()]
h = self.conv1(mfgs[0], (x, h_dst))
h = F.relu(h)
h_dst = h[: mfgs[1].num_dst_nodes()]
h = self.conv2(mfgs[1], (h, h_dst))
return h
sampler = dgl.dataloading.MultiLayerNeighborSampler([4, 4])
train_dataloader = dgl.dataloading.DataLoader(
graph,
train_nids,
sampler,
device=device,
batch_size=1024,
shuffle=True,
drop_last=False,
num_workers=0,
)
model = Model(graph.ndata["feat"].shape[1], 128, dataset.num_classes).to(device)
with tqdm.tqdm(train_dataloader) as tq:
for step, (input_nodes, output_nodes, mfgs) in enumerate(tq):
inputs = mfgs[0].srcdata["feat"]
labels = mfgs[-1].dstdata["label"]
predictions = model(mfgs, inputs)
Out:
0%| | 0/89 [00:00<?, ?it/s]
7%|6 | 6/89 [00:00<00:01, 51.93it/s]
13%|#3 | 12/89 [00:00<00:01, 52.22it/s]
20%|## | 18/89 [00:00<00:01, 51.91it/s]
27%|##6 | 24/89 [00:00<00:01, 52.09it/s]
34%|###3 | 30/89 [00:00<00:01, 51.97it/s]
40%|#### | 36/89 [00:00<00:01, 51.99it/s]
47%|####7 | 42/89 [00:00<00:00, 52.07it/s]
54%|#####3 | 48/89 [00:00<00:00, 51.82it/s]
61%|###### | 54/89 [00:01<00:00, 52.21it/s]
67%|######7 | 60/89 [00:01<00:00, 52.06it/s]
74%|#######4 | 66/89 [00:01<00:00, 52.57it/s]
81%|######## | 72/89 [00:01<00:00, 52.15it/s]
88%|########7 | 78/89 [00:01<00:00, 51.95it/s]
94%|#########4| 84/89 [00:01<00:00, 51.79it/s]
100%|##########| 89/89 [00:01<00:00, 52.07it/s]
Both update_all and the functions in nn.functional namespace
support MFGs, so you can migrate the code working for small
graphs to large graph training with minimal changes introduced above.
Writing GNN Modules for Both Full-graph Training and Stochastic Training¶
Here is a step-by-step tutorial for writing a GNN module for both full-graph training and stochastic training.
Say you start with a GNN module that works for full-graph training only:
class SAGEConv(nn.Module):
"""Graph convolution module used by the GraphSAGE model.
Parameters
----------
in_feat : int
Input feature size.
out_feat : int
Output feature size.
"""
def __init__(self, in_feat, out_feat):
super().__init__()
# A linear submodule for projecting the input and neighbor feature to the output.
self.linear = nn.Linear(in_feat * 2, out_feat)
def forward(self, g, h):
"""Forward computation
Parameters
----------
g : Graph
The input graph.
h : Tensor
The input node feature.
"""
with g.local_scope():
g.ndata["h"] = h
# update_all is a message passing API.
g.update_all(
message_func=fn.copy_u("h", "m"),
reduce_func=fn.mean("m", "h_N"),
)
h_N = g.ndata["h_N"]
h_total = torch.cat([h, h_N], dim=1)
return self.linear(h_total)
First step: Check whether the input feature is a single tensor or a pair of tensors:
if isinstance(h, tuple):
h_src, h_dst = h
else:
h_src = h_dst = h
Second step: Replace node features h with h_src or
h_dst, and assign the node features to srcdata or dstdata,
instead of ndata.
Whether to assign to srcdata or dstdata depends on whether the
said feature acts as the features on source nodes or destination nodes
of the edges in the message functions (in update_all or
apply_edges).
Example 1: For the following update_all statement:
g.ndata['h'] = h
g.update_all(message_func=fn.copy_u('h', 'm'), reduce_func=fn.mean('m', 'h_N'))
The node feature h acts as source node feature because 'h'
appeared as source node feature. So you will need to replace h with
source feature h_src and assign to srcdata for the version that
works with both cases:
g.srcdata['h'] = h_src
g.update_all(message_func=fn.copy_u('h', 'm'), reduce_func=fn.mean('m', 'h_N'))
Example 2: For the following apply_edges statement:
g.ndata['h'] = h
g.apply_edges(fn.u_dot_v('h', 'h', 'score'))
The node feature h acts as both source node feature and destination
node feature. So you will assign h_src to srcdata and h_dst
to dstdata:
g.srcdata['h'] = h_src
g.dstdata['h'] = h_dst
# The first 'h' corresponds to source feature (u) while the second 'h' corresponds to destination feature (v).
g.apply_edges(fn.u_dot_v('h', 'h', 'score'))
Note
For homogeneous graphs (i.e. graphs with only one node type
and one edge type), srcdata and dstdata are aliases of
ndata. So you can safely replace ndata with srcdata and
dstdata even for full-graph training.
Third step: Replace the ndata for outputs with dstdata.
For example, the following code
# Assume that update_all() function has been called with output node features in `h_N`.
h_N = g.ndata['h_N']
h_total = torch.cat([h, h_N], dim=1)
will change to
h_N = g.dstdata['h_N']
h_total = torch.cat([h_dst, h_N], dim=1)
Putting together, you will change the SAGEConvForBoth module above
to something like the following:
class SAGEConvForBoth(nn.Module):
"""Graph convolution module used by the GraphSAGE model.
Parameters
----------
in_feat : int
Input feature size.
out_feat : int
Output feature size.
"""
def __init__(self, in_feat, out_feat):
super().__init__()
# A linear submodule for projecting the input and neighbor feature to the output.
self.linear = nn.Linear(in_feat * 2, out_feat)
def forward(self, g, h):
"""Forward computation
Parameters
----------
g : Graph
The input graph.
h : Tensor or tuple[Tensor, Tensor]
The input node feature.
"""
with g.local_scope():
if isinstance(h, tuple):
h_src, h_dst = h
else:
h_src = h_dst = h
g.srcdata["h"] = h_src
# update_all is a message passing API.
g.update_all(
message_func=fn.copy_u("h", "m"),
reduce_func=fn.mean("m", "h_N"),
)
h_N = g.ndata["h_N"]
h_total = torch.cat([h_dst, h_N], dim=1)
return self.linear(h_total)
# Thumbnail credits: Representation Learning on Networks, Jure Leskovec, WWW 2018
# sphinx_gallery_thumbnail_path = '_static/blitz_3_message_passing.png'
Total running time of the script: ( 0 minutes 1.928 seconds)